
Mon process COMPLET pour vérifier l'indexation avec CLAUDE
(je te partage tout + skill indexation à copier-coller)

Bon, Je vais littéralement vous partager mon process complet, celui que j’utilise pour tous mes projets.
L’origine de cette édition, part de deux constats :
une page non indexée par Google = 0 trafic ;
avec le spam IA, même les bons contenus ont du mal à s’indexer en ce moment.
On pense être plus ou moins épargné par le phénomène, mais avec l’IA, les problèmes d’indexation se multiplient.
Ahref a analysé 2 millions de pages en 2023 : 38 % ne sont jamais indexées. Une autre étape Onely a été refaite cette fois-ci sur 4 millions de pages en 2024 : 51 %.
À cela, ajoutez un nom de domaine neuf, des mots-clés compétitifs, un maillage interne incomplet… et c’est toute votre production de contenu qui risque d’être invisible sur Google.
Voici les facteurs qui pèsent sur l’indexation de vos pages :

Mais aujourd’hui, on a Claude. Et avec Claude, on peut faire tourner un agent qui surveille tout ça à votre place, chaque semaine ou chaque mois, en quelques minutes.
Petit disclaimer : si vous avez plus de 500 URLs, mieux vaut encore passer par un outil classique.
Le process étape par étape que j’applique
1/ Lister les pages à surveiller
Un fichier en local avec toutes vos URLs (qu’il faudra donner à Claude)
Alternative plus légère : pointer Claude vers
votresite.com/sitemap.xml, qui est public.Meilleure solution : connecter en API google search console (un peu plus technique évidemment et peu engendrer un coût supp si +1000 urls par jour)
2/ Créer un skill pour l’agent dans Claude
Le skill rédigé pour la routine (je vous le donne à la fin)
Vous le déposez une fois dans la conversation Claude dédiée au site. Il y reste pour toutes les exécutions à venir.
3/ Lancer l’audit
Ponctuel : « Lance l’audit indexation sur cette liste. » → rapport dans 3 à 10 minutes selon le volume.
Si vous passez en local via le terminal, Récurrent :
/schedule→cron 0 1 1 * *→ rapport posté automatiquement le X de chaque mois, sans intervention de votre part.
4/ Lire le rapport dans Claude
Synthèse
Anomalies critiques détaillées
Anomalies mineures
Recommandations priorisées
5/ Transmettre les correctifs
À votre équipe ou prestataire technique.
Vérifier au prochain audit que les anomalies ont bien été corrigées.
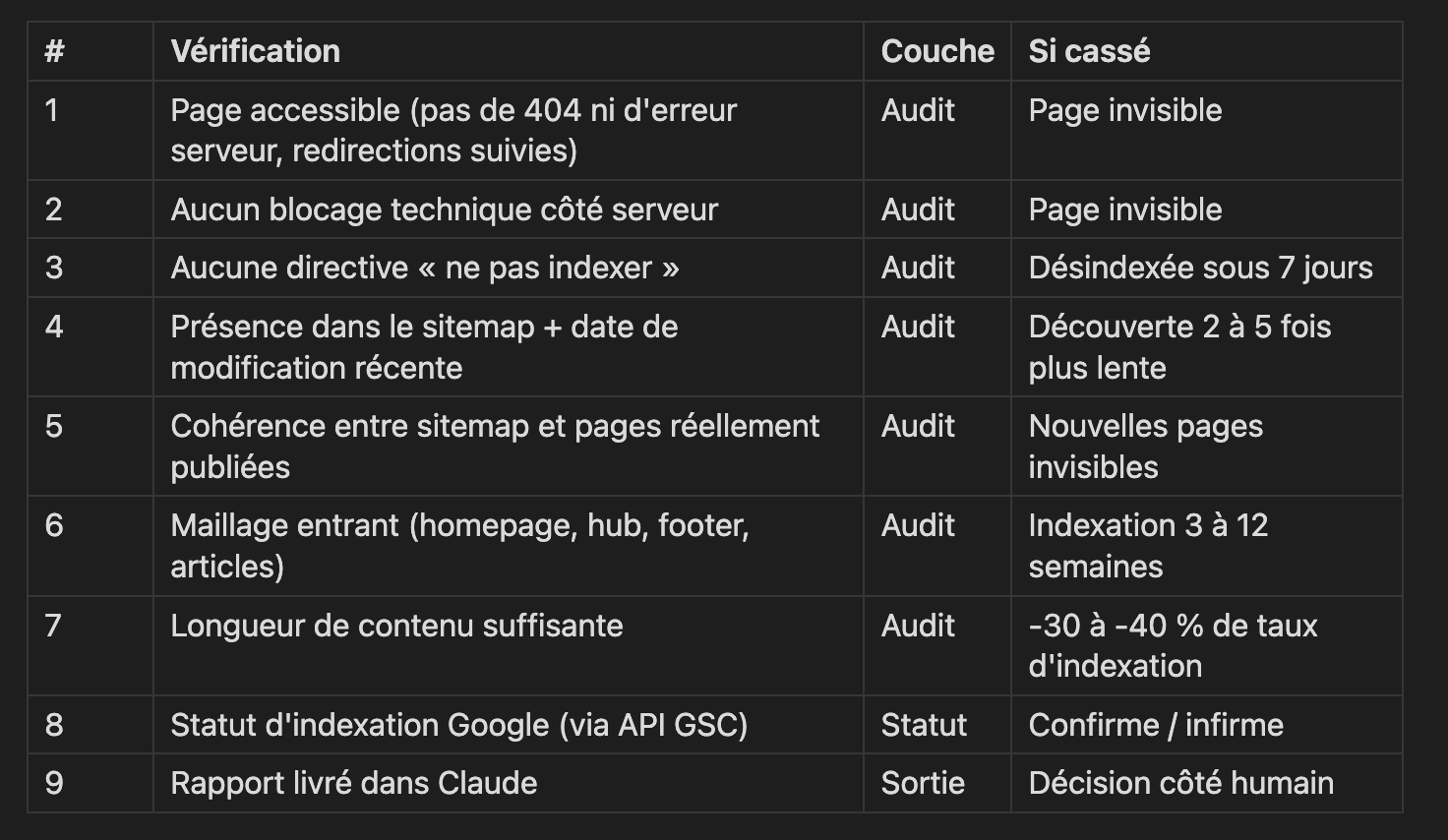
Les 9 points de vérification que Claude doit effectuer :
Et une partie de rapport ressemble à ça :
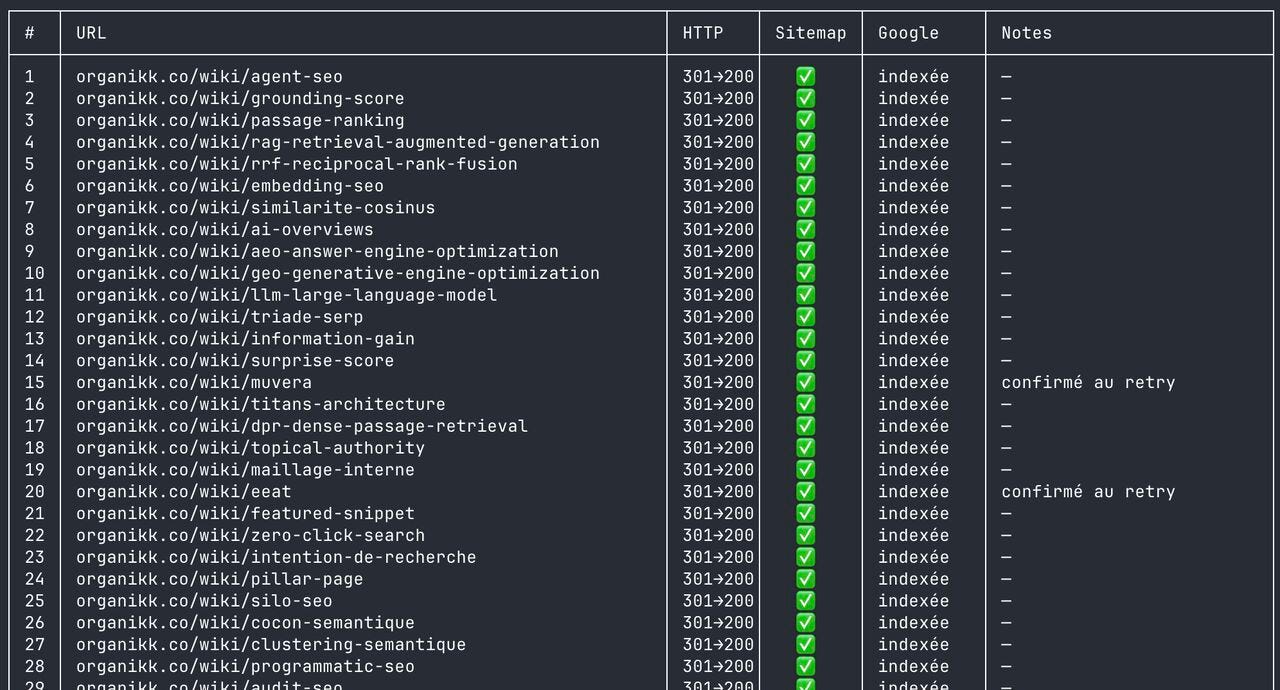
Ultra lisible, et surtout facilement partageable avec votre équipe ou votre client.
Bon, mais est-ce que c’est facile à mettre en place de votre côté ?
Coût.
Claude Pro à 20 €/mois suffit pour démarrer. Claude Max à 100–200 €/mois devient intéressant si vous exécutez beaucoup de routines en parallèle ou sur plusieurs sites clients. Les exécutions cloud sont incluses dans l’abonnement. Pas de surcoût à l’usage, mais vérifiez toujours de votre côté.
Compétences.
Pas besoin d’une équipe technique pour faire tourner la routine. Si vous savez lire un rapport et le transmettre à votre développeur ou à votre prestataire, c’est largement suffisant.
Délai.
Comptez environ 1 heure : connexion à Google Search Console, dépôt du workflow dans Claude, programmation de la récurrence, puis phase de tests. Faites plusieurs essais avant de lui confier entièrement votre audit d’indexation.
Compatibilité.
La méthode fonctionne sur tous les CMS : WordPress, Webflow, Shopify, ainsi que sur tous les sites construits sur des stacks classiques. La seule contrainte est d’avoir une propriété Google Search Console active sur votre domaine. Sinon, vous pouvez simplement fournir les URLs manuellement.
Point important :
Ce qu’on vient de voir fonctionne parfaitement. Pour faire simple, vous ouvrez une conversation Claude dans votre projet client, vous lancez l’audit, vous récupérez le rapport, puis vous transmettez les correctifs.
C’est la version minimum viable, et elle suffit pour démarrer, surtout si vous découvrez ce type de routine pour la première fois.
Mais le vrai gain arrive quand vous passez en local : Claude Code sur votre Terminal, plus GitHub, plus Obsidian. L’intérêt est que l’audit soit basé sur tout ce que Claude connaît de votre site, ou du site client, et qu’il puisse construire un historique complet de toutes les analyses effectuées.
Le gros avantage est également de pouvoir programmer les audits automatiquement, sans avoir à les lancer manuellement.
Je vous partage mon skill complet à donner à CLAUDE
Début :
# Skill — Audit d’indexation Claude
## Quand déclencher
- Audit ponctuel d’un site (avant un call commercial, après une refonte, après un déploiement de cluster)
- Monitoring mensuel récurrent sur un client en accompagnement
- Diagnostic d’une chute de trafic non expliquée
- Pré-flight d’un projet pSEO (vérifier que la base technique est saine avant de scaler)
## Input requis
| Source | Obligatoire |
|--------|-------------|
| Liste des URLs à monitorer (fichier dans le repo : `urls.txt`, `src/data/wiki.ts`, `src/data/articles.ts`) OU URL du `sitemap.xml` public du site | Oui |
| Domaine cible (ex : `site-client.fr`) | Oui |
| Périmètre du maillage à crawler (pages hubs : `/`, `/glossaire`, `/wiki`, footer, articles) | Recommandé |
| Service account GSC API (upgrade fiabilité) | Optionnel |
Minimum viable : une liste d’URLs et le domaine. Le reste se déduit.
## Architecture (3 couches)
1. Charger la liste des URLs (source de vérité humaine)
2. COUCHE A — Audit technique (causes potentielles)
3. COUCHE B — Statut d’indexation observable
4. COUCHE C — Reporting markdown
La séparation causes / statut est volontaire. Le check v1 ne regardait que le statut, donc disait “OK 200” même quand la page portait un `noindex` accidentel. Le check v2 sépare strictement les deux.
## Pipeline (9 checks)
### COUCHE A — Audit technique (causes)
#### 1. HTTP check (404/500, redirects)
Pour chaque URL :
```bash
curl -sIL -A "Mozilla/5.0" -o /dev/null -w "%{http_code}|%{url_effective}" {URL}Noter le code final ET la chaîne de redirections.
200 attendu. Toute redirection 301 → 200 systématique = dette à signaler (trailing slash, http → https).
2. robots.txt non bloquant
curl -s https://{domaine}/robots.txtPour chaque path, vérifier qu’aucune directive Disallow: ne le bloque pour User-agent: * ni User-agent: Googlebot.
3. Pas de balise noindex (HTML + en-tête HTTP)
curl -sL -A "Mozilla/5.0" {URL} | grep -i 'name="robots"'
curl -sIL {URL} | grep -i 'x-robots-tag'Signaler toute présence de noindex ou none.
4. Sitemap : présence + fraîcheur
curl -s https://{domaine}/sitemap.xmlPour chaque slug attendu, vérifier la présence d’une balise <loc> et lire le <lastmod> associé.
Flagger tout lastmod > 6 mois.
5. Cohérence sitemap ↔ source de vérité
Diff entre les slugs de la SOT (fichier humain) et les <loc> du sitemap :
Slugs présents dans la source mais absents du sitemap → à ajouter au build<loc> présents dans le sitemap mais absents de la source → orphelins sitemap
6. Maillage interne entrant
Crawler les pages hubs (/, /glossaire, /wiki, footer, sample d’articles) et compter les liens internes entrants par URL cible.
0 lien entrant = orpheline (critique)1 seul lien entrant = sous-maillée (à signaler)
7. Longueur de contenu (proxy thin content)
Pour chaque URL, extraire le texte du <main> ou <article> (à défaut du <body> sans <nav> et <footer>) puis compter les mots.
< 300 mots = thin content (à creuser)300–800 = court mais acceptable pour une fiche atomique> 800 = OK
COUCHE B — Statut d’indexation (sortie)
8. Indexation Google estimée (scraping site:)
curl -sL -A "Mozilla/5.0 (Macintosh...)" "https://www.google.com/search?q=site:{URL}&hl=fr"Garde-fous obligatoires :
Espacer les requêtes de 3 à 5 secondes (sleep 4)Détecter le blocage :
grep -E 'sorry/index|recaptcha|unusual traffic'Si bloqué : marquer “non testable — rate limit”, pas “non indexée”Retry une fois si réponse vide avant de conclureMarquer “indexée” si l’URL apparaît dans le HTML de réponse
Fiabilité estimée : ~40–60 % à cause du rate-limit Google.
Pour 100 % de fiabilité, voir la variante GSC API.
COUCHE C — Reporting
9. Rapport markdown
Structure obligatoire :
Synthèse en tête (X/N par dimension, ✅ pour validé, ⚠️ pour anomalie)Anomalies CRITIQUES (action immédiate) — noindex accidentel, page orpheline, 404 sur page businessAnomalies mineures — lastmod > 6 mois, sous-maillage, thin contentRecommandations priorisées (2 à 5 actions classées par impact estimé)Section “Limites du rapport” (ce qui n’a pas pu être testé et pourquoi)
Sortie obligatoire
# Indexation check — {domaine} — {date}
## Synthèse
Vérifications validées :
✅ {check} : X / N
✅ ...
Vérifications avec anomalies :
⚠️ {check} : X / N ({Y détails})
⚠️ ...
## Anomalies CRITIQUES (action immédiate)
⚠️ {URL} — {anomalie détectée}
{contexte : depuis quand, impact estimé en impressions ou clics}
→ {action concrète à mener}
## Anomalies mineures
- {liste compactée des points secondaires}
## Recommandations priorisées
1. {action 1} — {effort estimé}, {impact estimé}
2. {action 2} — ...
3. {action 3} — ...
## Limites de ce rapport
- {ce qui n’a pas pu être testé et pourquoi : rate-limit Google, JS rendu côté client, etc.}Garde-fous (NON NÉGOCIABLES)
Lecture seule sur le web public. Aucune requête authentifiée non explicitement autorisée.Aucune action de forçage d’indexation. Pas de soumission GSC, pas de force crawl.Pas de modification du site. Pas de PR sur les fichiers source. Sortie limitée à reports/ ou directement dans la conversation.Distinction stricte “non indexée” vs “non testable” dans le rapport.Priorité au signalement : un noindex accidentel sur une page business doit remonter en TOP du rapport, pas en ligne 47 d’un tableau.Si un check échoue, continuer les autres et signaler le problème dans la section “Limites”.
FIN
Pour mettre en place ce type de système SEO (indexation, audit, mots-clés etc.) et gagner du temps au quotidien :
Qadence évolue et se dote de 4 agents.
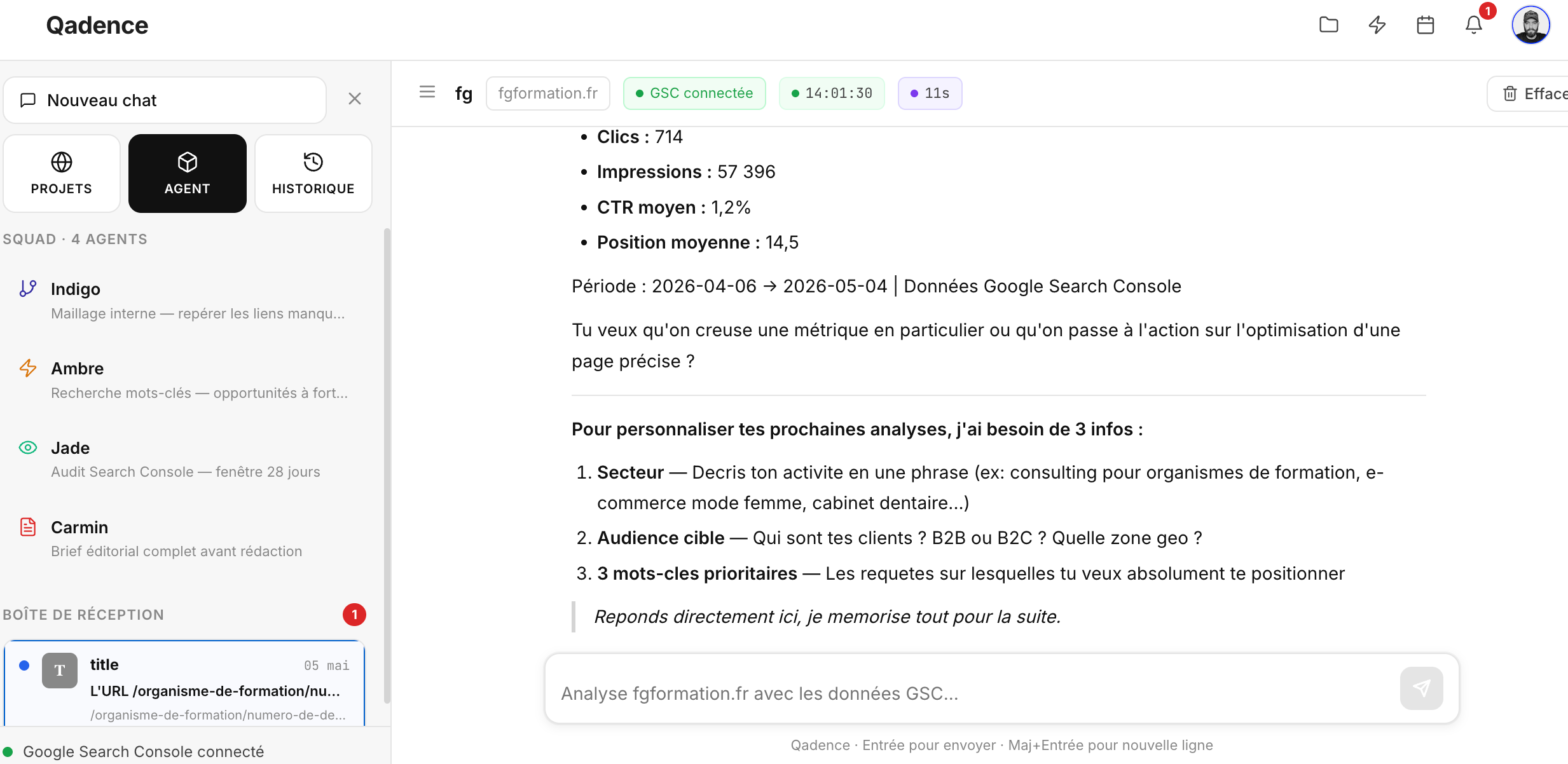
Avoir un assistant SEO dans sa poche pour 20e par mois :
Copilote SEO conversationnel branché sur ta Search Console (donc des données réelles)
4 agents squad spécialisés sur une tâche SEO précise
12 skills SEO (Audit & Diagnostic (Quick wins, Cannibalisation, Content gaps, Audit GSC), Stratégie (Mots-clés, Intention, Décodage requête, Maillage) etc.
Monitoring automatique en arrière-plan
⇢ Tu as apprécié cette édition de revue de presse et le format te plaît ? Like 💙 la newsletter pour que je puisse rédiger sur des sujets similaires.
