
La méthode CLAUDE pour travailler ta sémantique SEO
(+ mon skill audit sémantique COMPLET)

Pendant longtemps, le SEO reposait sur une équation relativement simple : choisir les bons mots-clés, obtenir des backlinks (ne surtout pas les acheter) et travailler un peu la technique.
Mais l’IA est arrivée et a profondément changé les règles du jeu.
Concrètement, la sémantique, puis les vecteurs sémantiques, sont venus remplacer une approche souvent très basique, voire peu qualitative. Le résultat de l’ancien modèle ? Des pages bourrées de mots-clés, avec peu d’informations nouvelles et une valeur ajoutée limitée pour l’utilisateur.
Parallèlement, les requêtes ont considérablement évolué. Nous sommes passés d’une moyenne de quelques mots à des requêtes pouvant dépasser 20 mots, notamment sur les LLMs. Le « mot-clé » tel que nous l’avons connu perd progressivement de son importance au profit d’une compréhension beaucoup plus fine du besoin réel de l’utilisateur, de son contexte et de son intention.
L’objectif n’est donc plus de répéter un terme un certain nombre de fois, mais de démontrer que l’on comprend le sujet dans toute sa complexité et que l’on est capable d’y répondre de manière pertinente, structurée et crédible.
D’ailleurs, Google a annoncé le 19 mai le plus grand changement de sa barre de recherche en plus de 25 ans. En gros, la nouvelle permettra d’effectuer des recherches avec du texte, des images, des vidéos ou des fichiers

Avec les LLM, la question n’est plus seulement de savoir quelle page ranker, mais quelle information sera retenue, citée et intégrée dans une réponse générée par l’IA, avec en ligne de mir évidemment : être cliqué par l’uitlisateur (car oui être cité ne sert pas à grand chose).
Je ne vous apprends rien, mais cette évolution est d’autant plus importante que le web traverse une phase de saturation de contenus générés par IA.
L’enjeu n’est plus simplement d’optimiser une page, ni même de bosser la sémantique de manière isolé, mais de contruire des sites qui sont de vrais entités sur le sujet, et qui ont une autorité thématique suffisante, la sméantique est un passage obligé pour atteindre cette objectif.
Je bosse depuis quelques semaines à transformer mes process en skills et en workflw dans l’idée d’intégré Claude à chaque étape pour mieux performer et gagner du temps.
Pour ceux qui veulent mettre en place leur système SEO personnalisé :
Outils classiques vs mon Claude (aïe!)
Bon, on commence avec un comparatif pour vous montrer l’intérêt de travailler sa sémantique directement avec Claude.
Pour faire simple, les outils sémantiques que l’on connait (sans les citer) scrapent le top 10 Google et te listent les termes statistiquement surreprésentés. Et je pense que tu vois venir le problème : tu finis par devenir la moyenne du Top 10.
On le sait, ce qui est moyen ne ressort pas sur Google. Globalement, si le Top 10 a déjà bien bossé son SEO, aucune raison que le dernier arrivé vienne prendre la place des anciens. C’est tout à fait logique.
J’ai demandé à Claude de me faire une comparaison entre mon approche et ce qui se fait sur le marché des outils SEO de sémantique classiques :

Comment construire une approche sémantique complète (et surtout qualitative)
L’idée, ce n’est pas juste de regarder ce que les autres ont fait. Non, l’idée, c’est de voir plus loin et d’apporter la meilleure réponse à l’utilisateur.
Voici mon approche et la manière dont j’ai entrainé Claude pour faire des audits sémantiques ↓ (ça vous permettra d’avoir la réflexion pour adapter le skill dans le futur)
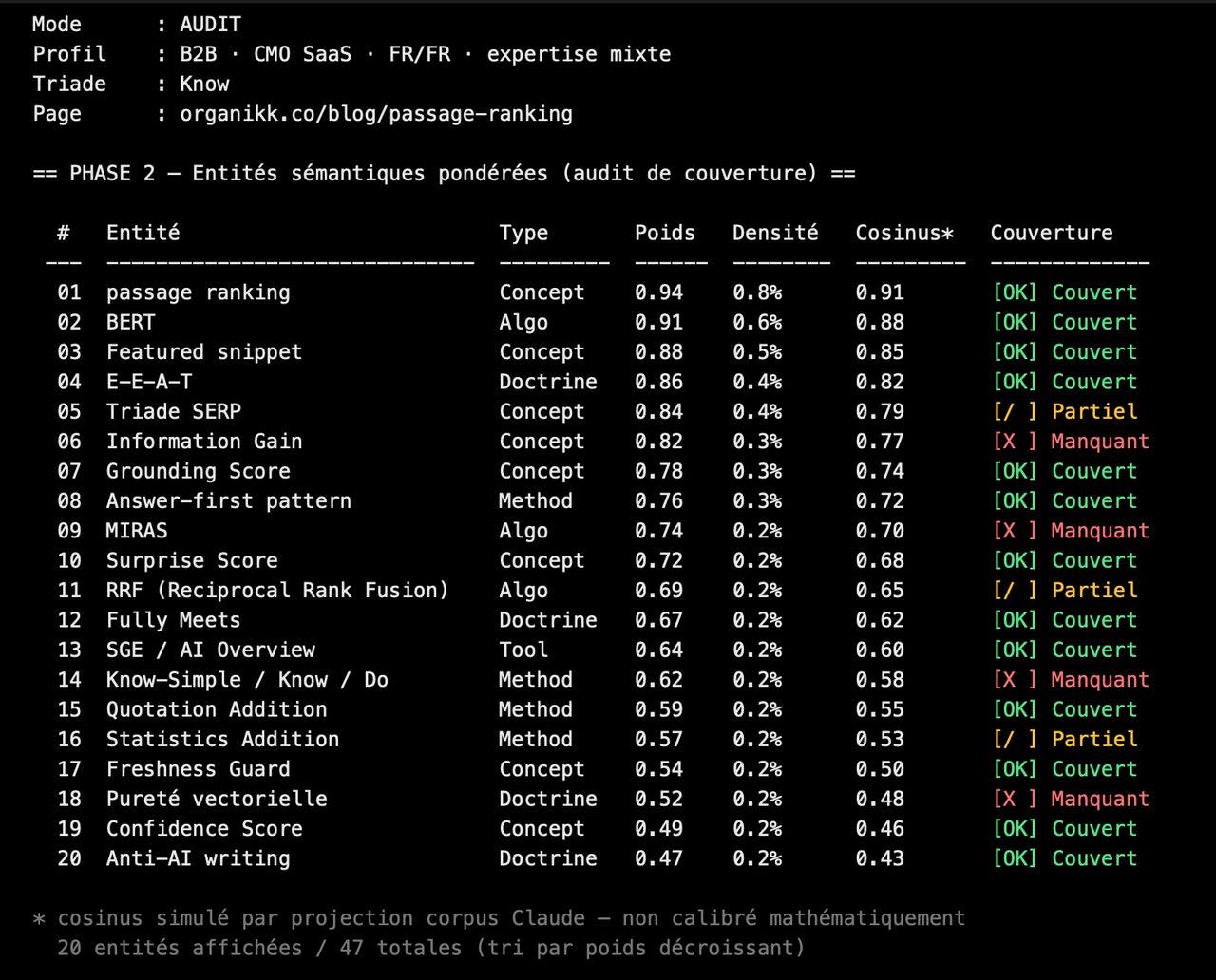
1. Décoder l’intention de recherche
Claude se demande pourquoi quelqu’un tape cette requête : soit il veut comprendre (Know), soit il veut agir (Do).
→ Tu sais immédiatement si ta page doit être un guide, un comparatif ou un outil interactif. Plus de pages fourre-tout que les IA (et bientôt Google) ne prendront que très peu en compte.
2. Pondèrer les entités sémantiques
Une entité = un concept, un outil, une méthode, une personne, un algorithme que ta page doit nommer pour que Google et les LLM la comprennent.
Le skill en sort 30 à 50, classées de la plus critique à la moins critique, avec un scoring sur 1,00 pour que ce soit plus lisible.
→ Tu sais exactement quoi mettre dans l’article, en quelle proportion, et pourquoi chaque entité y est.
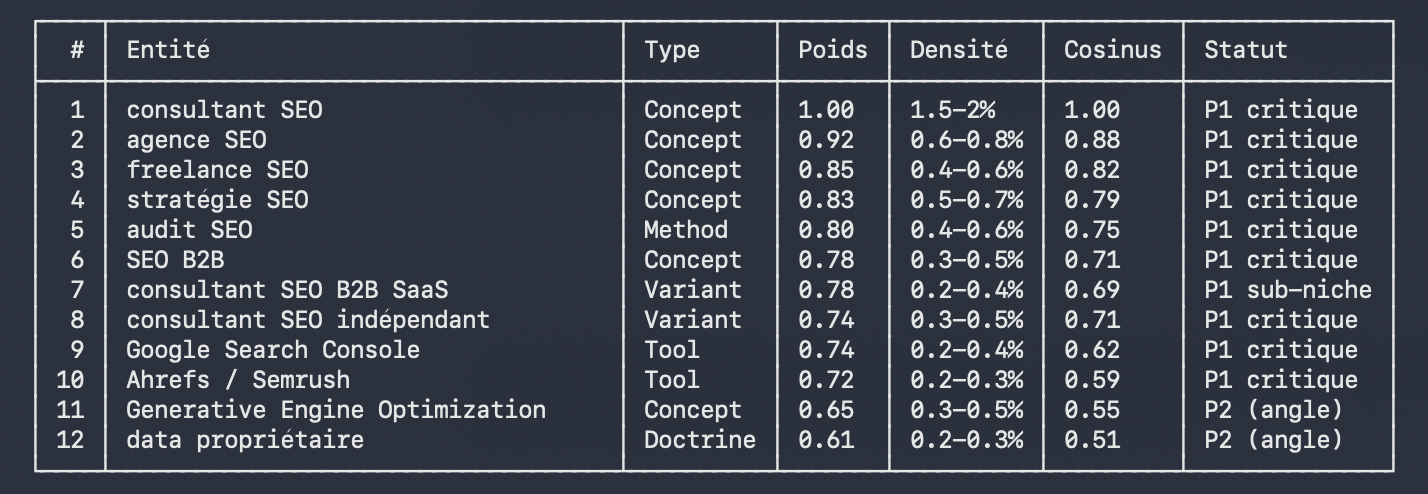
3. Repèrer le lexique sémantique
Le vocabulaire métier ne se résume pas à des mots-clés isolés. Google attend des expressions particulières et un vocabulaire expert, avec une fréquence là aussi particulière qui est attendue, ainsi qu’un nombre de cooccurrences.
4. Sortir les vrais points de douleur clients
La plupart des contenus sortent des objections clichés (« je veux des résultats », « je cherche du ROI »). Quel intérêt de répéter ce que le Top 10 sur Google a déjà dit ? Aucun.
L’idée est de devenir l’originalité de la SERP, et le site qui comprend vraiment ses utilisateurs. (L’IA ne pourra jamais remplacer ça, d’où l’importance du contexte que vous lui donnerez en entrée du skill.)
Le skill que je vous donne en fin de newsletter produit 10 frictions/objections concrètes avec un verbatim à haute surprise pour chacune : une phrase exacte qu’un expert dirait, si possible jamais publiée nulle part, ainsi que 3 objections priorisées.
→ Je le répète : donnez-lui un maximum d’infos type appels clients, tickets SAV, appels de vos commerciaux, etc., sinon le résultat sera générique.
5. Génèrer des preuves quantitatives
Les LLM citent les contenus chiffrés et sourcés. Ils ne veulent évidemment prendre aucun risque.
L’idée, c’est d’ajouter des chiffres datés avec leur source, et de scorer chaque preuve : haute confiance (utilisable), moyenne (à vérifier), basse (si possible, trouver une source complémentaire).
→ +41 % de chances d’être cité en AI Overview si tu intègres ces chiffres correctement. Bon, c’est à vérifier sur le terrain quand même.
6. Lister des éléments multimodaux
Sur certaines requêtes, un contenu texte ne suffira pas pour ranker.
L’idée, c’est d’attaquer des vecteurs multimodaux pour construire la meilleure page possible et mélanger tableaux, schémas, captures, vidéos courtes, calculateurs, outils, simulateurs, etc.
Le skill t’oriente vers les visuels à produire, dans quel format, pour répondre à quelle micro-intention.
→ Tu sais ce qu’il faut produire en plus du texte avant d’écrire ton brief à ton rédacteur, par exemple.
7. Identifier les gaps de contenu
Il faut être capable de comprendre ce que disent les autres, mais surtout ce qu’ils ne disent pas.
L’objectif est de se différencier pour apporter une information dont l’utilisateur a besoin et dont personne ne parle.
8. Construire votre approche propriétaire
Avoir identifié les gaps, c’est bien, mais pouvoir développer une réflexion dessus, c’est mieux.
Google veut un ton, une prise de position, une vision que tu dois être capable d’exprimer dans tes contenus.
Ici, vous êtes libres de pousser encore plus l’analyse. Le skill en compte 11, mais je ne me suis pas arrêté sur les plus techniques pour ne pas vous perdre totalement. 🙂
Le Skill complet à copier-coller
Tu peux le copier tel quel pour le brancher dans ton propre environnement Claude en local.
Skill complet :
---
name: seo-preparation-semantique
description: |
Engine autonome de préparation sémantique sans scraping SERP. Deux modes : CRÉATION (requête → carte vierge en 13 phases) et AUDIT (contenu existant → diff vs carte attendue + plan de correction P0/P1/P2).
Format de sortie : entités sémantiques pondérées (poids 0-1 + densité cible + cosinus simulé + justification + statut P1/P2/P3), lexique signature (n-grams + co-occurrences), pain points & verbatims Haute Surprise, preuves quantitatives (Confidence Score + Freshness Guard), multimodal, cartographie concurrentielle (5-10 acteurs), Gap analysis 3 vues (Gap Competitive Map + Content Gap Score + Surprise Score Sémantique 0-100), divergence calibrée Information Gain, FAQ stratégique (5-7 vecteurs), Structural Information GEO, matrice couverture × Mapping Triade SERP, patches KB.
Phase 0 informative (jamais bloquante) : alerte sur head term saturé / multi-intentions et propose sous-niches en annexe, mais produit toujours la carte complète.
Embeddings simulés : cosinus Phase 2 calibré sur le corpus Claude, marqué « simulé » dans chaque sortie. Pas de vraie API embedding — honnête sur le calcul.
TOUJOURS utiliser ce skill quand l'utilisateur dit :
- Mode Création : "prépare la sémantique", "carte sémantique", "préparation sémantique", "engine sémantique", "tout ce que ma page doit contenir", "fais-moi l'analyse sémantique de [requête]", "lance l'engine sur [requête]", "sémantique sans SERP", "analyse sémantique [mot-clé]", "prépa sémantique [requête]", "entités pondérées [requête]", "surprise score sémantique de [requête]".
- Mode Audit : "audite la sémantique de", "audit sémantique de cette page", "ma page couvre-t-elle [requête]", "compare ce contenu à la carte sémantique attendue", "qu'est-ce qui manque à mon article sur [requête]", "diff sémantique", "audit de couverture sémantique", "ma page ne ranke pas — qu'est-ce qui lui manque", "plan de correction sémantique".
Ce skill remplace les outils de scraping SERP. Il produit la matière sémantique brute (carte). Il NE produit pas la rédaction, ni la structure Hn finale, ni le hook — ces étapes sont en aval.
---
# Skill — Préparation sémantique sans SERP
Engine autonome qui produit la carte sémantique complète d'une page à écrire (Mode Création) ou audite la couverture sémantique d'un contenu existant (Mode Audit). Aucun scraping de SERP. La carte se construit depuis l'intention de la requête, le corpus du domaine, et l'expertise propre fournie en input.
## Détecter le mode
- **Requête + profil seuls** → Mode **CRÉATION**.
- **Requête + profil + contenu fourni** (texte collé, chemin de fichier, ou URL publique) → Mode **AUDIT**.
- Si ambigu, demander : « Tu veux créer la carte sémantique d'une page à écrire, ou auditer un contenu existant ? »
## Inputs requis
### Mode Création
| Variable | Valeur attendue | Statut |
|---|---|---|
| Requête cible | mot pour mot | Obligatoire |
| Pays / langue | FR/FR par défaut | Obligatoire |
| B2B/B2C + rôle | « B2B — CMO SaaS 50p » | Obligatoire |
| Objectif | Lead Gen / Conversion / Expertise | Obligatoire |
| Secteur | nommé | Obligatoire |
| Audience | junior / expert / mixte | Obligatoire |
| Localisation | ville ou « N/A » | Obligatoire |
| Expertise unique | une phrase signature | Recommandé |
### Mode Audit (en plus des inputs Création)
| Variable | Valeur attendue | Statut |
|---|---|---|
| Contenu à auditer | texte collé, chemin local, ou URL publique (robots.txt OK) | Obligatoire |
| Version cible | refonte / update freshness / élargissement / migration | Recommandé |
Si une variable obligatoire manque, poser **une seule question groupée** avant de produire.
## Pipeline — 13 phases en chaîne
```
Phase 0 — Filtre stratégique (informatif, jamais bloquant)
Phase 1 — Décodage micro-intentionnel + Action Engine flag
Phase 2 — Entités sémantiques pondérées (7 colonnes)
Phase 3 — Lexique signature (n-grams + co-occurrences)
Phase 4 — Pain points & verbatims Haute Surprise
Phase 5 — Preuves quantitatives (Confidence Score + Freshness Guard)
Phase 6 — Vecteurs multimodaux
Phase 7 — Cartographie concurrentielle (5-10 acteurs)
Phase 8 — Gap analysis 3 vues (8a Gap Competitive Map / 8b Content Gap Score / 8c Surprise Score Sémantique 0-100)
Phase 9 — Divergence calibrée Information Gain
Phase 10 — FAQ stratégique (5-7 vecteurs latents)
Phase 11 — Structural Information GEO
Phase 12 — Matrice couverture × Mapping Triade SERP
Phase 13 — Feedback loop KB (patches à archiver)
```
## Format détaillé par phase
### Phase 0 — Filtre stratégique (informatif, jamais bloquant)
Trois tests en amont. L'engine ne bloque jamais, il alerte et continue.
**0.1 Test de substitution LLM** — deux questions binaires :
1. ChatGPT répond déjà à cette requête à 80% ?
2. Si oui, peut-il faire mieux que l'utilisateur ?
Verdict : PASS / WARN / WARN sévère (flag « divergence obligatoire » en Phase 9 si WARN).
**0.2 Angle différenciant** — la requête est-elle un head term tapé pour 10 intentions différentes par 100 personnes différentes (`agence SEO`, `plombier Paris`) ? Si oui : WARN + propose des sous-niches en annexe (ex. `plombier 15e urgence nuit`).
**0.3 Pureté vectorielle** — UNE intention dominante ou plusieurs ? Si plusieurs : WARN + propose découpage en N pages.
Livrable Phase 0 :
```
PHASE 0 — Filtre stratégique
- Test LLM : [PASS / WARN — raison]
- Angle différenciant : [PASS / WARN — sous-niches proposées : (1) ... (2) ...]
- Pureté vectorielle : [PASS / WARN — N intentions : (1) ... (2) ...]
Verdict global : [GO franche / GO avec avertissement]
```
L'engine continue toujours vers Phase 1.
### Phase 1 — Décodage micro-intentionnel + Action Engine flag
Trois niveaux d'intention :
- **Intention principale** : taxonomie Know-Simple / Know / Do (remplace TOFU/MOFU/BOFU)
- **Sous-intentions** : 3 à 5 questions parallèles
- **Micro-intentions** : 15 à 25 questions granulaires
Profil utilisateur reformulé en une phrase tranchante.
**Action Engine flag** : si l'intention principale = `Do`, flag obligatoire — un outil interactif (calculateur, simulateur, générateur, audit) est requis pour viser Fully Meets. Une page Know textuelle ne ranke pas sur intention Do.
### Phase 2 — Entités sémantiques pondérées (format obligatoire 7 colonnes)
30 à 50+ entités par run. Format strict :
```
| # | Entité | Type | Poids (0-1) | Densité cible (%) | Cosinus estimé requête (0-1) | Justification | Statut |
|---|---|---|---|---|---|---|---|
| 1 | `passage ranking` | Concept | 0.94 | 0.8% | 0.91 | Brique du grounding, citée dans 3 papers MIRAS | P1 critique |
| 2 | `BM25` | Algo | 0.87 | 0.3% | 0.79 | Mécanique sous-jacente du Document Ranking | P1 critique |
```
- **Type** : Person / Concept / Tool / Method / Doctrine / Event / Location / Algo
- **Poids** : > 0.8 = entité pivot, 0.5-0.8 = supportive, < 0.5 = périphérique
- **Densité cible** : pivots 0.5-1%, supportives 0.2-0.5%, périphériques < 0.2% (sur 2000 mots)
- **Cosinus estimé** : projection Claude de la similarité entité ↔ requête, **marqué « simulé »** en pied de tableau
- **Justification obligatoire** : courte (paper, doctrine, co-occurrence). Aucune entité arbitraire.
- **Statut** : P1 critique (sans, ne ranke pas) / P2 (supportif) / P3 (bonus)
Pied de tableau obligatoire : *« Cosinus simulé par projection corpus Claude, non calibré mathématiquement. Pour calibration exacte : API embeddings Voyage / Cohere / OpenAI. »*
### Phase 3 — Lexique signature (n-grams + co-occurrences)
```
| N-gram / expression | Type | Fréquence attendue (sur 2000 mots) | Co-occurrence dominante | Statut |
|---|---|---|---|---|
| « passage ancré » | bigram | 2-3x | grounding-score, featured snippet | P1 |
| « ranker dans ChatGPT » | trigram | 1-2x | AIO, citation LLM | P1 |
```
Bigrams (2 mots), trigrams (3 mots), expressions multi-mots (> 3). Co-occurrence dominante = avec quelles autres entités/concepts ce n-gram apparaît systématiquement. Statut P1 = standard du domaine / P2 = bonus signature.
### Phase 4 — Pain points & verbatims Haute Surprise
Tableau de 10 lignes minimum :
```
| Micro-intention / Pain Point | Verbatim « Haute Surprise » | Preuve atomique attendue |
|---|---|---|
| [Frein précis nommé] | [Citation experte rarement verbalisée — zéro cliché] | [Sujet + Verbe + Donnée chiffrée] |
```
**Règles verbatims** :
- Frustration experte ou technique propre au métier
- Vocabulaire signature (verrouillé sur B2B/B2C du profil)
- Refus strict du cliché (« je veux du ROI », « je veux des résultats »)
Exemple :
- ❌ Cliché : « Je veux voir des résultats concrets »
- ✅ Haute Surprise : « La dernière agence m'envoyait des rapports de 40 pages où le seul KPI lisible était le nombre de backlinks, jamais croisé avec mon CRM »
**Règles preuves atomiques** : format binaire ou chiffré, vérifiable.
- ✅ « 73% des prospects B2B refusent un devis sans estimation immédiate »
- ❌ « Nous offrons un excellent service »
**Priorisation finale** : sortir 3 objections critiques selon `fréquence × intensité × différenciation`.
### Phase 5 — Preuves quantitatives (Confidence Score + Freshness Guard)
Génération depuis le training : chiffres datés avec source primaire, études, papers, jurisprudence, cas terrain.
**Confidence Score par preuve** :
| Niveau | Critère | Action |
|---|---|---|
| Haute | Source primaire récente identifiée, paper avec DOI, organisme officiel | Utilisable telle quelle |
| Moyenne | Source connue mais non vérifiée à 100% | Utilisable + fact-check obligatoire en aval |
| Basse | Reformulation indirecte, source secondaire, donnée approximative | **Remplacer par `[À SOURCER]`** |
**Règle absolue** : si confidence basse ou source inconnue → placeholder `[À SOURCER]` obligatoire. Aucun chiffre inventé.
**Freshness Guard** :
| Âge de la donnée | Statut |
|---|---|
| < 18 mois | Preuve fraîche — OK |
| 18-36 mois | Flag « à actualiser » — utilisable mais signalée |
| > 36 mois | Omise sauf paper fondateur (étude structurante non substituable) |
Format livrable : preuve + source + confidence + datation + flag fraîcheur + micro-intention couverte.
### Phase 6 — Vecteurs multimodaux
Tableaux, schémas, captures, photos, vidéos courtes, audio, données interactives. Pour chacun : objectif sémantique + format + micro-intention couverte.
### Phase 7 — Cartographie concurrentielle sans SERP
5 à 10 acteurs dominants identifiés depuis : training Claude + WebSearch ciblé (robots.txt OK) + KB interne si fourni.
```
| Acteur | Type | Angle dominant | Faiblesse identifiable |
|---|---|---|---|
```
Type : média / agence / expert individuel / institution / plateforme. Angle dominant = la thèse défendue. Faiblesse = ce qu'ils ne traitent pas, ne disent pas, ou refusent de voir.
### Phase 8 — Gap analysis (3 vues)
**8a. Gap Competitive Map** — matrice acteur × concept (P1 critiques uniquement, sinon trop chargé) :
```
| Acteur | Entité A | Entité B | Entité C | Entité D | Entité E | Gap exploitable |
|---|---|---|---|---|---|---|
| Acteur X | ✅ | ✅ | ❌ | ✅ | ❌ | Entités C + E |
| **GAP MARCHÉ** | — | — | — | — | **0/3** | **E = gap général** |
```
Une entité avec gap commun (jamais traitée par les 3 acteurs analysés) = opportunité d'attaque prioritaire.
**8b. Content Gap Score** :
| Axe | Définition | Cible |
|---|---|---|
| Couverture standard | % entités P1 que 80%+ des concurrents traitent | ≥ 70% (franchir Document Ranking) |
| Couverture surprise | % entités P1 traitées par < 20% des concurrents | ≥ 30% (passer Information Gain) |
Verdict :
- Standard < 70% → page n'a pas la base sémantique, ne ranke pas
- Standard ≥ 70% mais Surprise < 30% → indexable mais Low Surprise, oubliée par les modèles IA
- Standard ≥ 70% ET Surprise ≥ 30% → cible idéale
**8c. Surprise Score Sémantique 0-100** — moyenne pondérée de 4 composantes :
```
30% — Ratio entités propriétaires / entités totales
20% — Ratio verbatims Haute Surprise / verbatims totaux
25% — Distance lexicale propriétaire ↔ consensus (1 - cosinus simulé)
25% — Présence Quotation Addition + Statistics Addition (preuves verbatim + chiffrées avec source)
```
Échelle :
- **0-30** = Médiocrité statistique (oubli mémoriel garanti, refonte ou abandon)
- **30-60** = Acceptable mais réplicable (améliorations P1 obligatoires)
- **60-85** = Information Gain validé (publication OK)
- **85-100** = Inversion experte maximale
Avertissement obligatoire : *« Score calibré sur projection corpus Claude. Pour calibration exacte : audit GEO avec scores algorithmiques. »*
### Phase 9 — Divergence calibrée Information Gain
Benchmark Aggarwal KDD'24 (arXiv:2311.09735) — gains PAWC mesurés vs baseline :
| Méthode | Gain PAWC |
|---|---|
| Quotation Addition (citation verbatim) | +41% |
| Statistics Addition | +34% |
| Cite Sources | +29% |
| Authoritative (ton seul) | +13% |
Privilégier les angles divergents qui s'appuient sur **citation verbatim + statistiques sourcées**, pas sur le ton autoritaire.
Pour chaque axe de divergence, exiger :
- Acteur dominant ciblé (issu Phase 7)
- Entité de la Gap Competitive Map attaquée (Phase 8a)
- Type d'inversion (paresseuse vs juste mais contre-intuitive)
- Forme (citation verbatim, stat propriétaire, cas terrain, donnée externe sourcée)
Critère final : un expert dirait *« tiens, je n'avais pas vu ça comme ça »*.
### Phase 10 — FAQ stratégique (5-7 vecteurs latents)
5 à 7 questions = 5 à 7 vecteurs sémantiques distincts. Zéro chevauchement avec le corps.
Règles strictes :
- Chaque question répond à une micro-intention **non couverte par le corps**
- Réponse courte, actionnable, citable isolément (AI Overview ready)
- Verrouillage B2B/B2C selon profil Phase 1
- Aucune question pédagogique générique (« qu'est-ce que X »)
- Priorité aux questions Know / Comparatif / Do non traitées dans le corps
La FAQ absorbe la périphérie sémantique pour préserver la pureté vectorielle du corps.
### Phase 11 — Structural Information GEO
Finding SAGEO Arena 2025 (Kim et al., Yonsei, arXiv:2602.12187) : optimiser le body seul **dégrade** le retrieval (−4.54 Hit Rate). Optimisation structurelle apporte +22% Hit Rate. Structural + Statistics combinés : **+35%**.
```
| Champ | Contrainte sémantique | Entité(s) à inclure (Phase 2) |
|---|---|---|
| Title (≈10 mots) | Mot-clé exact + différenciateur | Entité principale + angle divergence |
| Meta description (155 char) | Answer-first + bénéfice mesurable | Entité principale + verbe d'action |
| H1 | Mot-clé sémantique + promesse | Entité principale + Surprise Gap |
| H2 (5-8 prévus) | Chaque H2 = un vecteur sémantique distinct | Une entité ou concept par H2 |
| Schema.org | Type adapté à l'intention | Article + FAQPage + LocalBusiness (si géo) + HowTo (si Do) + VideoObject (si multimodal) |
```
### Phase 12 — Matrice couverture × Mapping Triade SERP
Croise micro-intentions × couches Phases 2-11. Vérifie qu'aucune micro-intention n'est orpheline.
**Mapping Triade SERP** — chaque livrable est tagué selon la phase Google qu'il nourrit :
```
| Couche produite | Phase Triade SERP cible | Mécanisme |
|---|---|---|
| Entités nommées + Structural Information | Phase 1 — Document Ranking (admission) | BM25 + RankBrain |
| Concepts structurants + preuves + grounding + n-grams | Phase 2 — Passage Ranking (densité par bloc) | DPR / Muvera + BERT |
| FAQ + answer-first + Surprise Gap | Phase 3 — Generation (AIO, citation LLM) | Grounding + Confidence Score |
```
Sans ce mapping, le rédacteur en aval ne sait pas où placer quoi.
### Phase 13 — Feedback loop KB
À la fin de chaque exécution, identifier les éléments à versionner dans le KB local (si l'utilisateur en a un) :
```
À ajouter à /concepts/ : concept-X.md (résumé en une phrase)
À ajouter à /entities/ : entité-Y.md (rôle dans le domaine)
À ajouter à /competitors/ : concurrent-Z.md (angle + faiblesse)
À ajouter à doctrine.md : doctrine-W (formulation tranchée)
À archiver dans /verbatims/ : verbatim-V.md (frustration experte rare)
À archiver dans /lexique/ : n-gram-N.md (expression signature)
```
L'utilisateur valide ou ajuste avant d'archiver. Sans cette phase, l'engine ne progresse pas — avec, il s'auto-améliore à chaque passage. Si l'utilisateur ne dispose pas d'un KB structuré, lister simplement les éléments candidats à archiver pour qu'il les copie où il veut.
## Template d'output final
```
PRÉPARATION SÉMANTIQUE — Requête : "[...]"
Profil : [B2B/B2C, rôle, secteur, objectif, audience, géo]
== PHASE 0 — Filtre stratégique (informatif) ==
- Test LLM : [PASS / WARN]
- Angle différenciant : [PASS / WARN]
- Pureté vectorielle : [PASS / WARN]
Verdict : [GO franche / GO avec avertissement]
Annexe sous-niches (si WARN) : [...]
== Livrables 1-13 ==
1. Micro-intentions (3 niveaux + profil + Action Engine flag)
2. Entités sémantiques pondérées (tableau 7 colonnes + avertissement « cosinus simulé »)
3. Lexique signature (n-grams + co-occurrences + statut P1/P2)
4. Pain points (10+ lignes) + 3 objections priorisées
5. Preuves quantitatives (Confidence Score + Freshness Guard + datation)
6. Multimodal
7. Cartographie concurrentielle (5-10 acteurs)
8. Gap analysis :
8a. Gap Competitive Map (matrice acteur × concept)
8b. Content Gap Score (% standard vs % surprise + verdict)
8c. Surprise Score Sémantique : XX/100 — [verdict] + avertissement
9. Divergences (Information Gain calibré + acteur ciblé + entité attaquée)
10. FAQ stratégique (5-7 questions = 5-7 vecteurs)
11. Structural Information GEO (title / meta / H1 / H2 / schema)
12. Matrice couverture × Mapping Triade SERP
13. Patches KB à archiver
```
## Règles absolues
- **Aucun scraping SERP**, jamais. Pas Google, pas Bing, pas autre moteur.
- **Robots.txt strict** pour tout WebFetch. Si bloqué : training Claude + demande à l'utilisateur, jamais bypass.
- **Cosinus simulé toujours marqué** : sortie Phase 2 + Phase 8c avec avertissement « simulé par projection corpus Claude ».
- **Confidence Score obligatoire** sur chaque preuve chiffrée. Si basse ou inconnue → `[À SOURCER]`. Aucun chiffre inventé.
- **Freshness Guard** : preuves > 36 mois omises sauf paper fondateur.
- **Phase 0 jamais bloquante** : alerte WARN + sous-niches en annexe, produit toujours la carte complète.
- **Ne pas rédiger** : pas de H1 final, pas de hook, pas d'architecture Hn finale, pas de CTA, pas de prose narrative.
- **Une page = une intention** (pureté vectorielle). Si pluralité d'intentions Phase 0.3 → WARN + N sous-cartes en annexe.
- **Anti-cliché obligatoire** Phase 4 : pas de « je veux du ROI », pas de « je veux des résultats ».
- **Phase 2 — Justification obligatoire** : chaque entité avec sa justification courte. Pas d'entité arbitraire.
## Concepts mobilisés (définitions inline — pour usage autonome)
- **Triade SERP** : les 3 phases successives par lesquelles passe une requête sur Google moderne — Document Ranking (filtre d'admission via BM25/RankBrain), Passage Ranking (densité sémantique par bloc via DPR/Muvera/BERT), Generation (citation dans AI Overview / Featured Snippet / réponse LLM).
- **Information Gain** : standard Google formalisé dans les Quality Rater Guidelines (page 42) — un contenu sans effort qui reprend ce qui existe déjà reçoit la note la plus basse. Benchmark Aggarwal KDD'24 (arXiv:2311.09735) mesure les méthodes qui gonflent l'IG.
- **Confidence Score** : niveau de fiabilité d'une preuve chiffrée (haute / moyenne / basse) qui détermine si elle est utilisable telle quelle, à fact-checker, ou à remplacer par `[À SOURCER]`.
- **Freshness Guard** : règle d'âge des preuves — < 18 mois fraîche, 18-36 mois à flagger, > 36 mois omise (sauf paper fondateur structurel).
- **Action Engine flag** : drapeau levé en Phase 1 si l'intention est `Do` — la page doit alors embarquer un outil interactif (calculateur, simulateur, générateur, audit) pour viser la note Fully Meets des Quality Raters.
- **Pureté vectorielle** : une page = une intention. Multi-intentions dilue le vecteur sémantique et fait sortir la page du retrieval.
- **Answer-first pattern** : la réponse directe doit être en début de section/page, pas après 800 mots de mise en contexte. Validé par le finding Positional Bias des rerankers LLM (arXiv:2604.03642).
- **Grounding Score** : mesure de fidélité aux sources — critère de tri prioritaire des LLM modernes, plus important que le keyword stuffing.
- **Know-Simple / Know / Do** : taxonomie d'intention qui remplace TOFU/MOFU/BOFU pour l'ère LLM. Know-Simple = fait isolé, Know = compréhension complète, Do = action transactionnelle.
- **Surprise Gap** : la fracture entre ce que tous les concurrents disent (consensus) et ce que toi seul dis (angle propriétaire). Plus le gap est large, plus le contenu est mémorisé par les modèles IA.
- **Structural Information GEO** : finding SAGEO Arena 2025 (Kim et al., arXiv:2602.12187) — optimiser uniquement le body dégrade le retrieval, optimiser la couche structurelle (title, meta, headings, schema) + ajouter des statistiques sourcées apporte +35% Hit Rate.
## Sauvegarde (optionnel)
Si l'utilisateur dispose d'un vault structuré (Obsidian, dossier markdown organisé), proposer de sauvegarder l'output dans `<vault>/queries/prepa-semantique-YYYY-MM-DD-slug.md`. Sinon, output dans la conversation seule.
## Mode Audit — différences
En Mode Audit, chaque phase produit **3 colonnes** au lieu d'une : Attendu (calculé Mode Création) / Couvert dans le contenu actuel / Gap + action de correction.
Trois statuts par couche :
- ✅ Couvert : élément attendu présent et conforme → validation
- ❌ Gap : élément attendu absent ou non conforme → correction à planifier
- ⚠️ Hors scope : élément présent qui ne correspond à aucune couche attendue → suppression ou déplacement (FAQ, autre page)
Le statut « Hors scope » est critique : il préserve la pureté vectorielle.
**Plan de correction priorisé** livré à la fin :
```
PLAN DE CORRECTION — Contenu : "[titre/URL/chemin]"
Surprise Score Sémantique actuel : XX/100 — [verdict]
P0 — Bloquants (à corriger avant publication)
- [Phase X — Couche Y] Gap : [description] → Action : [verbe + objet précis]
P1 — Importants (avant prochaine vague de mises à jour)
- [...]
P2 — Améliorations (sur les versions suivantes)
- [...]
ÉLÉMENTS HORS SCOPE détectés :
- [Citation du contenu] → Raison : pollue le vecteur → Action : déplacer / supprimer
Score de couverture global : X/11 couches couvertes
```
- **P0** : Gap sur Phase 11 (Structural) ou phase Triade SERP entière non couverte → ne franchit pas l'admission Google
- **P1** : Gap sur Phase 4 (pain points), Phase 9 (divergence), Phase 5 (preuves), ou Surprise Score < 60 → indexée mais Low Surprise
- **P2** : Gap sur Phase 10 (FAQ), Phase 6 (multimodal), Phase 13 (patches KB) → ranke mais ne maximise pas la Triade SERP phase 3
````
Pour mettre en place votre système SEO et améliorer vos process au quotidien :
Tester les nouvelles fonctionnalités sur Fusionn (Youtube, Reddit etc.)
⇢ Tu as apprécié cette édition de revue de presse et le format te plaît ? Like 💙 la newsletter pour que je puisse rédiger sur des sujets similaires.
